


许多人(包括我)称足球为“不可预测的比赛”,因为一场足球比赛有不同的因素可以改变最终比分。
在某种程度上这是真的。
很难预测最终比分或比赛的获胜者,但在预测比赛的获胜者时却并非如此。 在过去的5年里,拜仁慕尼黑赢得了所有的德甲冠军,而曼城则赢得了4次英超联赛冠军。
这是巧合吗? 我不这么认为。
有不同的预测方法。 我可以构建一个奇特的机器学习模型并为其提供多个变量,但在阅读了一些论文后,我决定给泊松分布(Poisson distribution)一个机会。
为什么? 好吧,让我们看一下泊松分布的定义。
泊松分布是一种离散概率分布,描述了在固定时间间隔或机会区域内发生的事件数量。
如果我们将进球看作是一场足球比赛 90 分钟内可能发生的事件,那么我们可以计算 A 队和 B 队在一场比赛中进球数的概率。
但这还不够。 我们仍然需要满足泊松分布的假设:可计算事件的数量(一场比赛可以有 1、2、3 或更多的目标)事件的发生是独立的(一个进球的发生应该不会影响另一个进球的概率)事件发生的速率是恒定的(在某个时间间隔内进球的概率对于其他相同长度的时间间隔应该完全相同)两个事件不能同时发生(两个目标不能同时发生)
毫无疑问,假设 1 和 4 得到满足,但假设 2 和 3 部分成立。 也就是说,让我们假设假设 2 和 3 始终为真。
当我预测欧洲顶级联赛的获胜者时,我绘制了前 4 大联赛过去 5 年每场比赛进球数的直方图。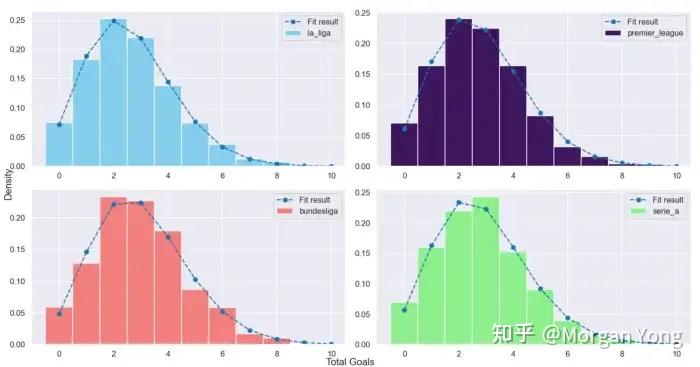 4个联赛进球数直方图
4个联赛进球数直方图
如果你看一下任何联赛的拟合曲线,它看起来就像泊松分布。
现在我们可以说,可以使用泊松分布来计算一场比赛中进球数的概率。
这是泊松分布的公式。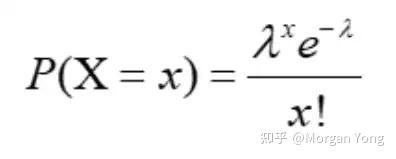
为了做出我考虑的预测:
λ(Lambda):90 分钟内进球的中位数(A 队和 B 队)
x:A队和B队在一场比赛中的进球数
要计算 λ(Lambda),我们需要每个国家队的平均进球数/失球数。
我们无法在没有数据的情况下启动项目,因此,现在我们将使用 Python 和 Beautiful Soup 把迄今为止举办的所有世界杯 (1930-2018) 和 2022 年世界杯的赛程中提取数据。
我们将使用 bs4 来抓取网站,使用 lxml 来解析 HTML 文档,并使用 requests 向目标网站发送请求。
这是您需要在终端中运行以安装这些库的命令。
除了上面的库之外,我们还将安装 pandas 以更好地管理我们要提取的数据。
现在让我们开始coding。
在本文中,我们将从迄今为止举办的所有世界杯中抓取数据。 也就是说,为了更友好,我们将先从一个世界杯(2014 年巴西)中抓取数据开始。在第 2 部分中,我们将使用第 1 部分中编写的代码从所有世界杯中提取数据。
要使用 Beautiful Soup 提取数据,我们需要创建一个Soup。 此Soup使用我们之前安装的 lxml 解析器以及将要解析的 HTML 内容。
要获取网站的 HTML 内容,我们需要向网站发送请求,然后获取响应文本。
现在是时候通过网络抓取足球比赛了。 为此,我们必须确定一种模式(Pattern),使我们不仅可以抓取一场比赛,而且可以抓取比赛的所有比赛。
为了轻松找到一种模式,首先,我们必须通过浏览器的开发者工具(可通过右键单击“检查”打开)来检查网站。
这是我浏览网站后发现的一种模式。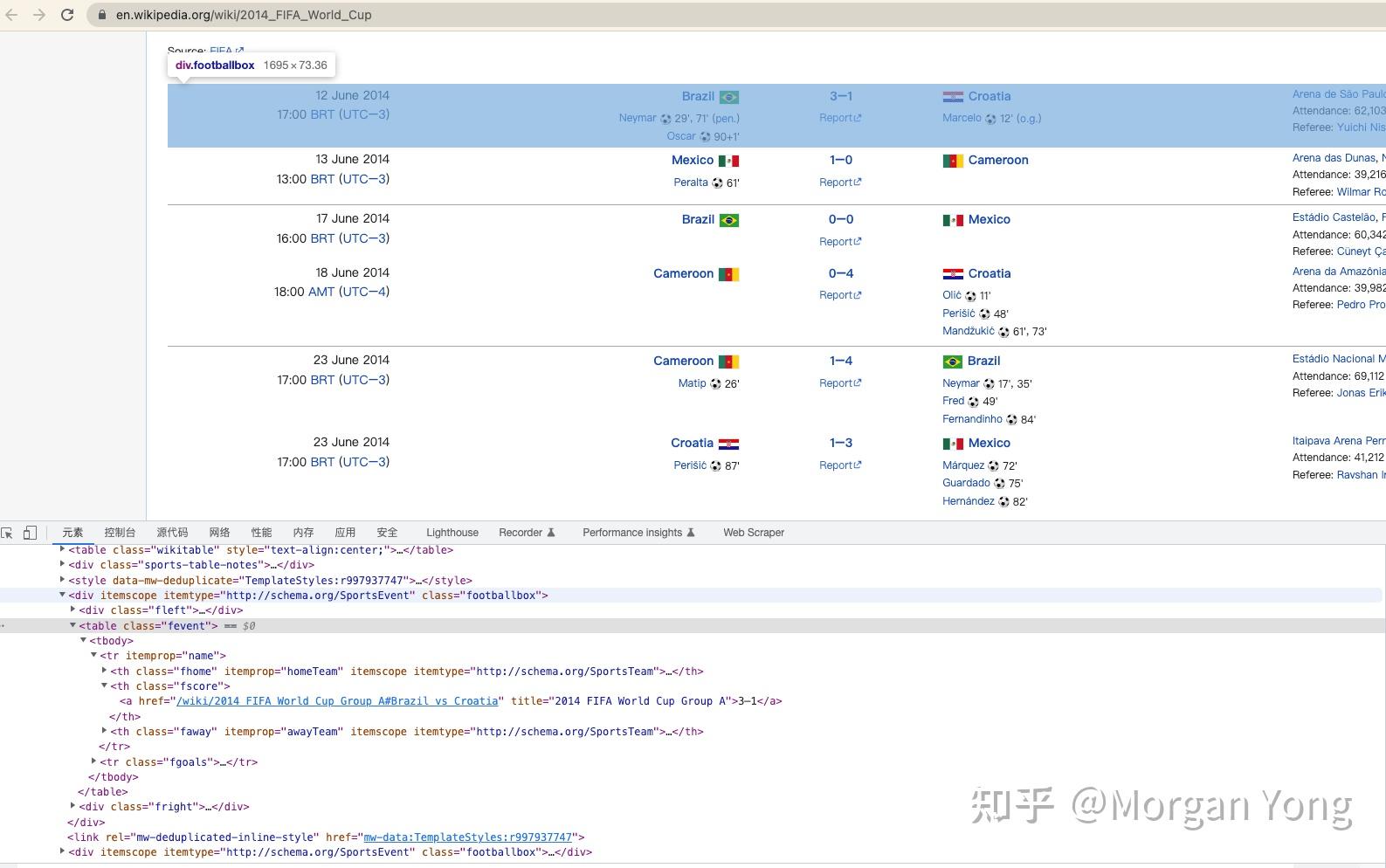
正如您所看到的,每场比赛都在一行中,该行由上面以蓝色突出显示的 HTML 节点表示。
现在要用我们的Soup提取所有匹配项,我们必须使用 .find_all 方法。 此方法需要 2 个输入:HTML标签名称和CSS类名称。
将所有比赛行存储在一个名为 matches 的列表中。
现在我们的匹配列表中包含所有匹配项,我们必须遍历它以提取特定信息。
在这种情况下,我们将提取主/客队和得分数据。 然后我们将它们存储在空列表中,以便稍后将它们放入表中。
要获取主队数据,我们需要先检查它,然后我们必须复制标签名称和类名称。 比分和客队也是如此。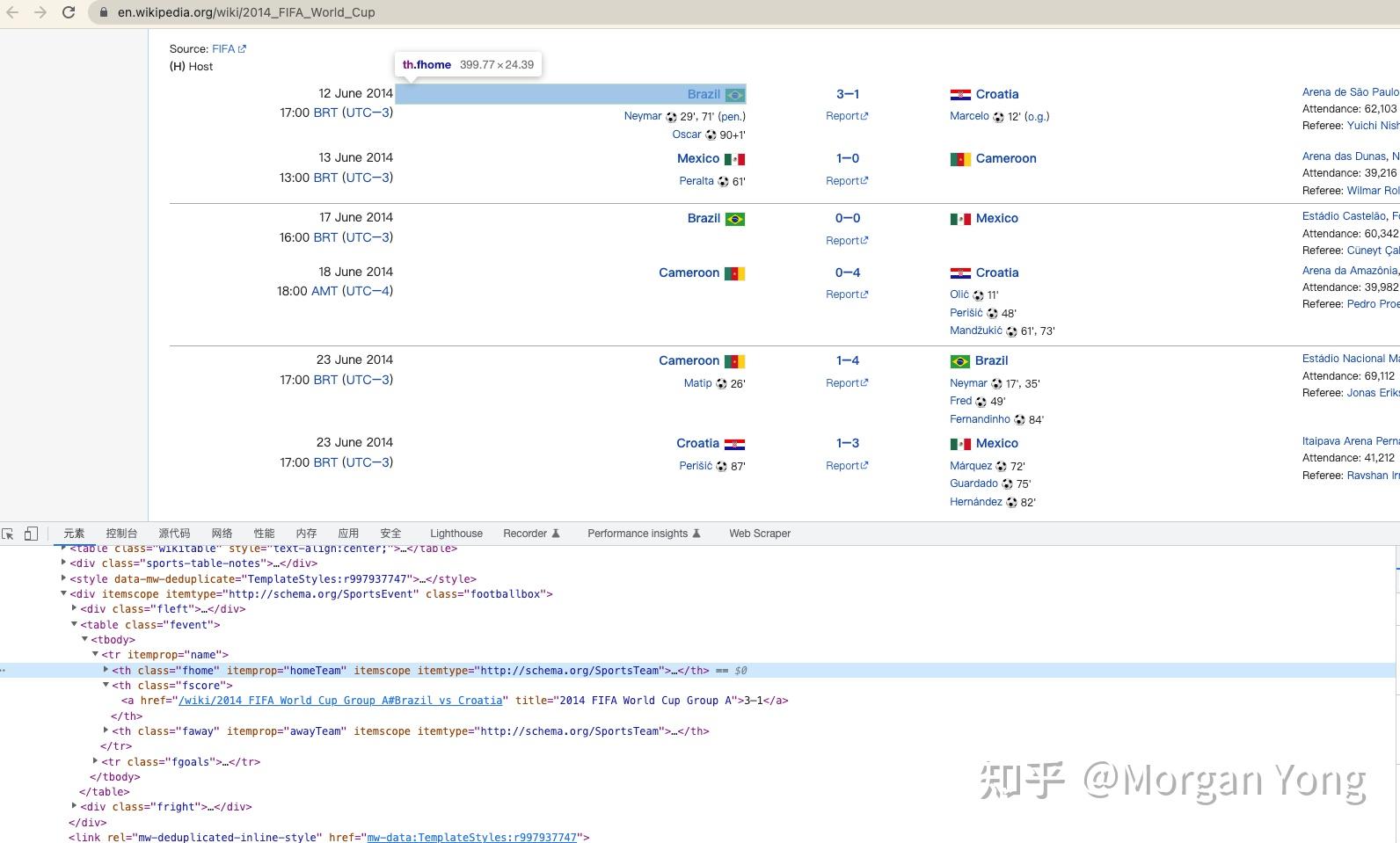
最后,我们使用 .get_text 获取元素的文本。
Dataframes 非常适合在 Python 中管理数据。 我们将从主场、比分和客场列表创建一个Dataframe。 除此之外,我们将创建一个名为“year”的列,其中包含世界杯的年份(本例为 2014 年)
最后,我们将数据框导出到 CSV 文件。
既然我们知道如何抓取一个世界杯,是时候抓取所有的世界杯数据了! 为此,首先,我们需要在链接中找到一种模式(Pattern)。
让我们来看看2014年、2018年和2022年世界杯的链接:
你注意到这个模式了吗? 除了举办世界杯的年份外,这些链接是相同的。
我们可以重新编写我们的web变量来考虑这种模式:
现在我们可以将我们的代码放入一个以年份year作为输入的函数中。
现在是时候使用我们的 get_matches 函数获取 1930 年到 2018 年的历史数据了。
我们还可以获得即将到来的2022年卡塔尔世界杯的赛程。
现在我们得到了 2 个 CSV 文件。 一个包含2022年前的历史数据,另一个是2022年的数据。
在收集了 1930 年到 2018 年所有世界杯比赛的数据后,我可以计算出每个国家队的平均进球数和失球数。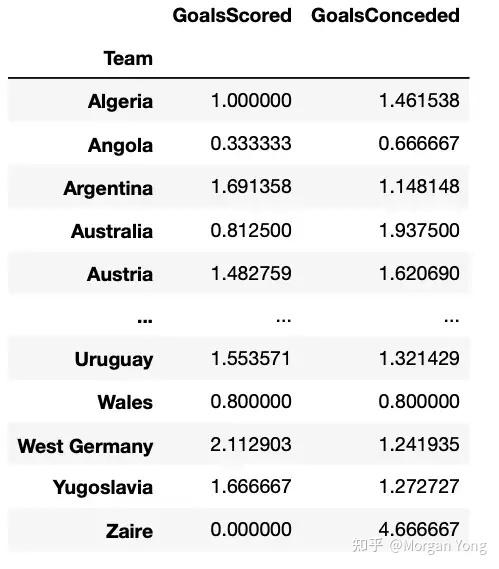
在我对欧洲 4 大联赛的预测中,我考虑了主客场因素,但由于在世界杯上几乎所有球队都在中立场地比赛,因此我在分析中没有考虑这个因素。
一旦我获得了每支国家队的进球数/失球数,我就创建了一个函数来预测每支球队在小组赛阶段将获得的积分数。
下面是我用来预测每个国家队在小组赛阶段将获得多少分的代码。
简单的说,predict_points 计算主队和客队将获得多少分。 为此,我使用公式 average_goals_scored * average_goals_conceded 计算了每个团队的 λ(Lambda)。
然后我模拟了一场比赛的所有可能比分,从 0-0 到 10-10(最后一个比分只是我目标范围的极限)。 一旦我有了 λ(Lambda) 和 x,我就使用泊松分布的公式来计算 p。
如果比赛分别以 1-0(主场获胜)、1-1(平局)或 0-1(客场获胜)结束,则 prob_home、prob_draw 和 prob_away 会累积 p 的值。 最后,使用以下公式计算分数。
如果我们使用 predict_points 来预测英格兰对美国的比赛,我们会得到这个。
这意味着英格兰将获得 2.23 分,而美国将获得 0.59 分。 我得到小数是因为我使用的是概率。
如果我们将此 predict_points 函数应用于小组赛阶段的所有比赛,我们将获得每组的第一名和第二名,从而获得淘汰赛中的以下比赛。
对于淘汰赛,我不需要预测积分,而是预测每组的胜者。 这就是为什么我在之前的 predict_points 函数的基础上创建了一个新的 get_winner 函数。
简单来说,如果points_home大于points_away则主队胜,否则客队胜。
如果我再次使用 get_winner,我可以预测世界杯的获胜者。 这是最终结果!
通过再次运行该函数,我知道赢家是:
巴西! Brazil!巴西! Brazil!巴西! Brazil!巴西! Brazil!巴西! Brazil!巴西! Brazil!巴西! Brazil!
这就是我使用 Python 和泊松分布预测 2022 年世界杯的结果。 要查看完整代码,请查看我的 GitHub。

文章声明:以上内容(如有图片或视频在内)除非注明,否则均为雨燕体育直播_雨燕无插件体育直播_雨燕直播体育_雨燕体育直播nba原创文章,转载或复制请以超链接形式并注明出处。
本文作者:admin本文链接:https://123wssy.com/post/1946.html
还没有评论,来说两句吧...